Quản lý bộ nhớ trong Hệ điều hành
Ngày đăng: 2026-04-19
Lời nói đầu
Đây tiếp tục là một bài viết trong chuỗi bài viết về Hệ điều hành, chủ đề ngày hôm nay là về những khái niệm cơ bản và các vấn đề liên quan trong cách mà hệ điều hành quản lý bộ nhớ, các phương pháp quản lý bộ nhớ trong thiết kế hệ điều hành.
Trước khi bắt đầu ta cần phải củng cố lại một số kiến thức:
Một chương trình phải được đưa vào bộ nhớ và trở thành tiến trình thì mới có thể thực thi được.
Các chương trình nằm trong đĩa sẽ được đưa vào một Input Queue để chờ được cấp phát RAM và thực thi.
User programs đi qua một vài bước trước khi được thực thi. Cụ thể hơn là phải Binding Address (Gắn kết địa chỉ)
Gắn kết địa chỉ:
Nói một cách dễ hiểu, khi bạn viết code, các biến và hàm của bạn chỉ là những cái tên. Để máy tính chạy được, những cái tên này phải được "gắn" (bind) vào một địa chỉ vật lý cụ thể trên thanh RAM.
Quá trình gắn kết địa chỉ lệnh và dữ liệu của chương trình có thể diễn ra ở 3 giai đoạn khác nhau:
Compile time (Lúc biên dịch):
- Đặc điểm: Nếu ngay từ lúc biên dịch code, hệ thống đã biết chắc chắn chương trình này sẽ được đặt ở vị trí nào trong RAM, trình biên dịch sẽ tạo ra mã tuyệt đối (absolute code). Nghĩa là địa chỉ RAM được ghi cứng ngắc vào trong file chạy.
- Hạn chế: Nếu sau này vị trí RAM đó bị chương trình khác chiếm mất hoặc hệ thống muốn đổi chỗ, bạn bắt buộc phải biên dịch lại toàn bộ code (recompile). Ngày nay phương pháp này rất ít được sử dụng cho các ứng dụng thông thường vì nó thiếu linh hoạt.
Load time (Lúc nạp/tải vào bộ nhớ):
- Đặc điểm: Nếu lúc biên dịch người ta chưa biết chương trình sẽ nằm ở đâu trong RAM, trình biên dịch sẽ tạo ra mã có thể tái định vị (relocatable code).
- Cách hoạt động: Các địa chỉ trong code lúc này chỉ mang tính tương đối (ví dụ: "cách đầu chương trình 10 byte"). Khi bạn click đúp để mở ứng dụng, Hệ điều hành (HĐH) sẽ tìm một vùng RAM trống, nạp chương trình vào đó và cộng thêm vị trí bắt đầu vào các địa chỉ tương đối kia để ra địa chỉ vật lý thật.
Execution time (Lúc thực thi/Lúc chạy):
- Đặc điểm: Đây là phương pháp linh hoạt nhất và được hầu hết các HĐH hiện đại sử dụng. Việc gắn địa chỉ vật lý bị trì hoãn cho đến tận lúc chương trình đang chạy (run time).
- Cách hoạt động: Điều này cho phép một tiến trình (process) có thể bị HĐH bế từ chỗ RAM này sang chỗ RAM khác ngay cả khi nó đang hoạt động.
- Yêu cầu phần cứng: Để làm được điều vi diệu này mà không làm sập chương trình, nó cần sự hỗ trợ đặc biệt từ phần cứng (thường là bộ quản lý bộ nhớ - MMU). Nó dùng thanh ghi cơ sở (base register) và thanh ghi giới hạn (limit register) để liên tục dịch và kiểm tra địa chỉ ngay trong lúc chạy, đảm bảo chương trình luôn truy cập đúng vùng nhớ của mình.
Địa chỉ luận lý (Logical Address) và địa chỉ vật lý (Physical Address):
Đây là những khái niệm cơ bản để ta có thể hiểu được quản lý bộ nhớ trong hệ điều hành.
Địa chỉ luận lý: Được tạo ra bởi CPU nhằm giúp cho việc quản lý bộ nhớ trở nên dễ dàng và hiệu quả hơn cho các tiến trình. Nó không tồn tại thực tế nên nó còn được gọi là địa chỉ ảo (Virtual Address). Từ các địa chỉ ảo này ta sẽ ánh xạ nó tới địa chỉ vật lý (Physical Address) nằm trên bộ nhớ thật như RAM thông qua MMU.
Địa chỉ vật lý: Là các địa chỉ thật sự nằm trên RAM nơi mà các Process (bao gồm data hoặc các lệnh) được lưu vào. Nhưng khi truy xuất thì CPU phải truy xuất chúng thông qua MMU.
Giống như một địa chỉ nhà vậy. Thay vì ta dùng tọa độ để đánh dấu như "10°50'41.6"N 106°44'03.1"E", rất khó đọc và nhớ, thì ta sẽ gán cho nó một địa chỉ. Chẳng hạn như "số 120, Yên Lãng" chẳng hạn, rất dễ nhờ và dễ quản lý. Và ta sẽ cần một nơi để lưu và tra địa chỉ vật lý từ địa chỉ ảo như Google Maps ngoài đời thì đó chính là MMU.
| Logical Address | Physical Address |
|---|---|
| Generated by the CPU during program execution | Generated by the Memory Management Unit (MMU) |
| Logical Address Space is set of all logical addresses generated by CPU in reference to a program | Physical Address is set of all physical addresses mapped to the corresponding logical addresses |
| User can view and access the logical address of a program | User can never view physical address of program |
| Can change during program execution (due to relocation, paging, etc.) | Generally fixed once assigned in memory |
| The user can use the logical address to access the physical address | The user can indirectly access physical address but not directly |
| Logical address can be change | Physical address will not change |
| Virtual address | Real address |
Memory-Management Unit (MMU)
Đây là một thiết bị phần cứng được dùng để ánh xạ địa chỉ luận lý sang địa chỉ vật lý. Nó sử dụng Thanh ghi tái định vị (Relocation Register) để định vị các địa chỉ luận lý được tạo ra bởi tiến trình của người dùng khi được đưa vào RAM. Nó sẽ cộng giá trị của Relocation Register vào địa chỉ luận lý để xác định địa chỉ vật lý trên RAM.
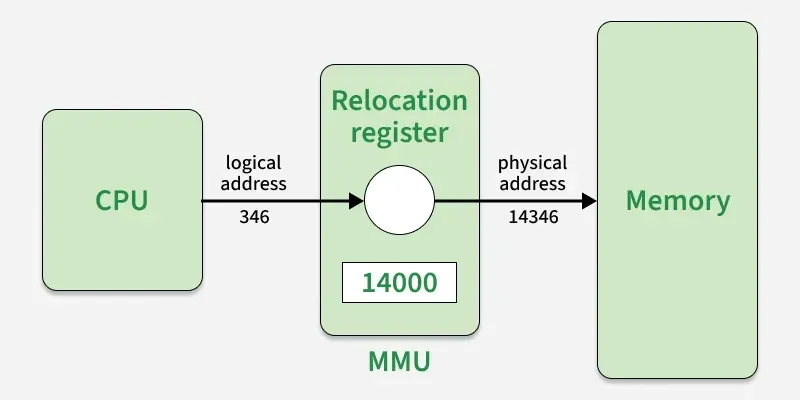
Bởi vì người dùng và các tiến trình sẽ không thể làm việc với địa chỉ vật lý nên MMU là một thành phần tối quan trọng trong hệ thống máy tính.
Dynamic Loading và Dynamic Linking:
Dynamic Loading (Nạp động) và Dynamic Linking (Liên kết động) – là những kỹ thuật cực kỳ thông minh được sinh ra để tiết kiệm dung lượng RAM và tối ưu bộ nhớ khi nạp chương trình vào RAM.
Dynamic Loading (Nạp động)
Hiểu đơn giản, nạp động tuân theo nguyên tắc "gọi đến đâu, nạp vào RAM đến đó".
Cách hoạt động: Một hàm hoặc đoạn code (routine) sẽ nằm im trên ổ cứng và không được tải vào bộ nhớ (RAM) cho đến khi chương trình thực sự gọi nó ra chạy.
Ưu điểm lớn nhất: Giúp tối ưu hóa không gian bộ nhớ cực tốt. Những hàm nào không bao giờ được dùng đến thì sẽ không bao giờ tốn 1 byte RAM nào.
Trường hợp sử dụng: Rất hữu ích khi phần mềm của bạn có những khối code khổng lồ nhưng rất hiếm khi xảy ra. Ví dụ điển hình nhất là các module xử lý lỗi (error handling). Bình thường app chạy mượt thì không sao, chỉ khi nào crash hay lỗi nặng thì hệ thống mới lôi cục code xử lý lỗi đó nạp vào RAM.
Yêu cầu: Kỹ thuật này không cần hệ điều hành phải hỗ trợ gì đặc biệt cả. Chính người lập trình viên (programmer) sẽ là người chủ động thiết kế logic code để tự quản lý việc này.
Dynamic Linking (Liên kết động)
Nếu Dynamic Loading liên quan đến việc khi nào nạp code vào RAM, thì Dynamic Linking liên quan đến việc cách các phần mềm dùng chung các thư viện (libraries). Thay vì gói tất cả mọi thứ vào chung một file cài đặt khổng lồ (gọi là Static Linking), hệ thống sẽ tách các thư viện ra riêng (chính là các file .dll trên Windows hoặc .so trên Linux).
Cách hoạt động: Việc liên kết code của bạn với các thư viện bên ngoài bị trì hoãn cho đến tận lúc chương trình đang chạy (execution time).
Cơ chế "Stub" (Đoạn mã mồi): Thay vì chứa toàn bộ code của thư viện, chương trình của bạn chỉ chứa một mẩu code tí hon gọi là stub. Chức năng của stub là dùng để định vị xem cái thư viện thật sự đang nằm ở đâu trong RAM.
Quá trình thay thế: Khi chương trình chạy tới đoạn cần dùng thư viện, nó đụng phải cái stub. Cái stub này sẽ đi tìm địa chỉ thật của thư viện, sau đó tự thay thế bản thân nó bằng địa chỉ thật đó rồi chạy hàm. Từ những lần gọi sau, chương trình sẽ phi thẳng đến địa chỉ thật mà không cần hỏi đường cái stub nữa.
Yêu cầu: Khác với nạp động, liên kết động bắt buộc phải có sự tham gia của Hệ điều hành. HĐH cần phải đi kiểm tra xem thư viện đó đã có sẵn trong bộ nhớ chưa, và quản lý các quyền truy cập để nhiều ứng dụng có thể xài chung một thư viện cùng lúc.
Swapping
Trong hệ điều hành đa nhiệm thì khi các ứng dụng hoạt động sẽ sinh ra nhiều process khác nhau. Điều này dẫn đến một vấn đề là khi một số process có xu hướng không được sử dụng trong một thời gian dài, trong khi các process khác đang nằm trong Input-Queue chờ được nhận RAM, điều này dẫn đến quản lý tài nguyên không hiệu quả. Dẫn đến sự ra đời của cơ chế Swapping.
Khi một vài process không được hoạt động trong thời gian dài và Input Queue đang không rỗng, các process đó sẽ được đưa tạm thời vào các Backing Store để tiết kiệm RAM, sau đó sẽ được đưa lại vào RAM khi cần thiết.
Việc đưa process ra khỏi RAM được gọi là Swap out, ngược lại được gọi là Swap in. Ngoài ra còn có thuật ngữ Roll out, Roll in cũng dùng để chỉ việc Swap nhưng thường được dùng trong trong các thuật toán lập lịch dựa trên độ ưu tiên:
- Roll out: Nếu một tiến trình ưu tiên cao (VIP) xuất hiện mà RAM đã đầy, hệ điều hành sẽ "tống khứ" một tiến trình ưu tiên thấp hơn ra ổ cứng.
- Sau khi "VIP" chạy xong, tiến trình bị đuổi lúc nãy mới được nạp trở lại RAM.
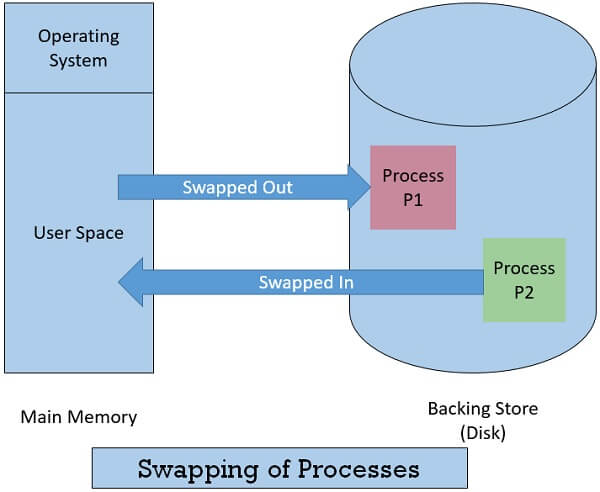
Backing Store là một vùng trong SSD hoặc HDD có tốc độ đủ nhanh và dung lượng đủ lớn để lưu lại Memory Images (lưu lại trạng thái hiện tại của chương trình) của tất cả người dùng và hệ thống phải có khả năng truy cập trực tiếp các Memory Images này để có thể nạp lại các Process vào RAM một cách nhanh nhất có thể.
Để Swapping hiệu quả thì ta cần phải giảm Swap time, chiếm phần lớn thời gian trong Swap time là Transfer time (thời gian chuyển dữ liệu từ RAM vào Ổ cứng).
Việc di chuyển dữ liệu giữa RAM (cực nhanh) và Ổ cứng (chậm hơn nhiều) là nút thắt cổ chai. Tổng thời gian hoán đổi tỉ lệ thuận với dung lượng bộ nhớ bị hoán đổi.
Ví dụ: Nếu bạn swap một tiến trình chiếm 1GB RAM, nó sẽ tốn thời gian lâu hơn gấp 10 lần so với một tiến trình chỉ chiếm 100MB. Đó là lý do tại sao các hệ điều hành hiện đại cố gắng swap càng ít càng tốt, hoặc chỉ swap những "trang" (pages) thực sự cần thiết thay vì toàn bộ tiến trình.
Cấp phát vùng nhớ liên tục
Trong khi hệ điều dành cư trú ở vùng nhớ thấp bắt đầu từ địa chỉ 0 của RAM cùng với Interupt vector. Thì chương trình người dùng sẽ được chứa trong vùng nhớ cao.
Interupt Vector: là một bảng chứa các giá trị là địa chỉ bắt đầu của các ISR (Interupt Service Routine) là các chương trình phục vụ cho các loại ngắt khác nhau.
Để các chương trình không xâm phạm các vùng nhớ của hệ điều hành thì OS sẽ sử dụng cơ chế Cấp phát đơn phân đoạn (Single-partition allocation) là mô hình đơn giản để bảo vệ bộ nhớ bằng cách sử dụng các thanh ghi phần cứng:
- Relocation register (Thanh ghi tái định vị): Chứa địa chỉ vật lý nhỏ nhất (điểm bắt đầu) mà tiến trình được phép sử dụng.
- Limit register (Thanh ghi giới hạn): Chứa phạm vi (kích thước) của địa chỉ logic.
- Cơ chế bảo vệ:
- Mọi địa chỉ logic CPU tạo ra phải nhỏ hơn giá trị trong thanh ghi Limit ($logical_address < limit$).
- Nếu thỏa mãn, địa chỉ vật lý thật sẽ được tính bằng: $Physical = Logical + Relocation$.
- Nếu không thỏa mãn, phần cứng sẽ báo lỗi truy cập trái phép.
Tuy nhiên cấp phát đơn phân đoạn chỉ hoạt động tốt trên hệ điều hành đơn chương trình, gây lãng phí dung lượng RAM còn trống, trong khi các máy tính hiện đại đều chạy hệ điều hành đa chương. Do đó dẫn đến sự ra đời của Cấp phát đa phân đoạn (Multiple-partition allocation) là một mô hình chia bộ nhớ RAM thành các "lỗ hổng" khác nhau để cấp phát cho nhiều ứng dụng cùng một lúc, cho phép nhiều chương trình được trú ngụ trên RAM cùng một lúc.
- Hole (Lỗ hổng): Là các khối bộ nhớ còn trống. Ban đầu, toàn bộ RAM cho người dùng là một "lỗ hổng" khổng lồ. Khi các tiến trình nạp vào và thoát ra, các lỗ hổng với kích thước khác nhau sẽ nằm rải rác khắp nơi trong RAM.
- Cách hoạt động: * Khi một tiến trình mới xuất hiện, HĐH sẽ tìm một "lỗ hổng" đủ lớn để chứa nó.
- Nếu lỗ hổng quá lớn, nó sẽ được chia đôi: một phần cho tiến trình, phần còn lại vẫn là lỗ hổng (nhưng nhỏ hơn).
- Quản lý: HĐH phải ghi chép lại hai danh sách:
- a) Allocated partitions: Những vùng nào đã có chủ.
- b) Free partitions (Holes): Những vùng nào đang trống để cấp cho người sau.
Vấn đề nảy sinh: Chọn lỗ hổng nào? Trong sơ đồ Multiple-partition, một câu hỏi lớn đặt ra là: Nếu có nhiều lỗ hổng đủ lớn, bạn nên chọn cái nào? Đây là lúc các thuật toán như First-fit, Best-fit, và Worst-fit* xuất hiện.
- First-fit: Thấy lỗ nào đủ rộng đầu tiên là nhét vào luôn (Nhanh nhất).
- Best-fit: Tìm lỗ nào vừa khít nhất (Tiết kiệm không gian nhất nhưng mất thời gian tìm).
- Worst-fit: Tìm lỗ to nhất để nhét vào (Để lại lỗ hổng sau khi chia vẫn đủ to cho người khác).
Tuy nhiên việc cấp phát đa phân đoạn như vậy có thể khiến cho RAM bị Phân mảnh (Fragmentation), tức là khi các chương trình không khớp 100% với các lỗ trống (rất hay xẩy ra) sẽ dẫn đến các vùng nhớ còn rống rất nhỏ mà không thể sử dụng được như trên ảnh sau:
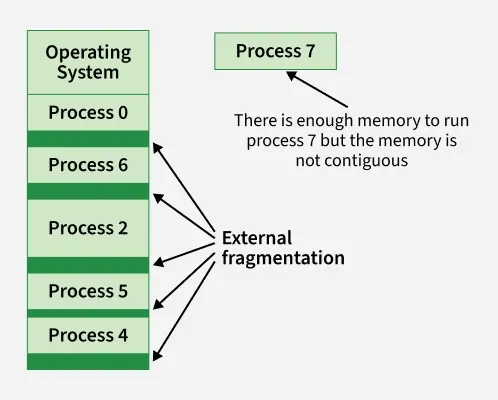
Đây chính là hiện tượng External Fragmentation, khi mà tổng các dung lượng còn trống là đủ nhưng nó lại không liên tục để cấp phát cho các chương trình khác.
Còn khi một chương trình được cấp phát bộ nhớ lớn hơn cái thực sự nó cần, thì sự chênh lệch nhỏ ấy sẽ không được sử dụng đến gây ra hiện tượng Internal Fragmentation.
Có thể nói Internal Fragmentation là tiền đề cho External Fragmentation.
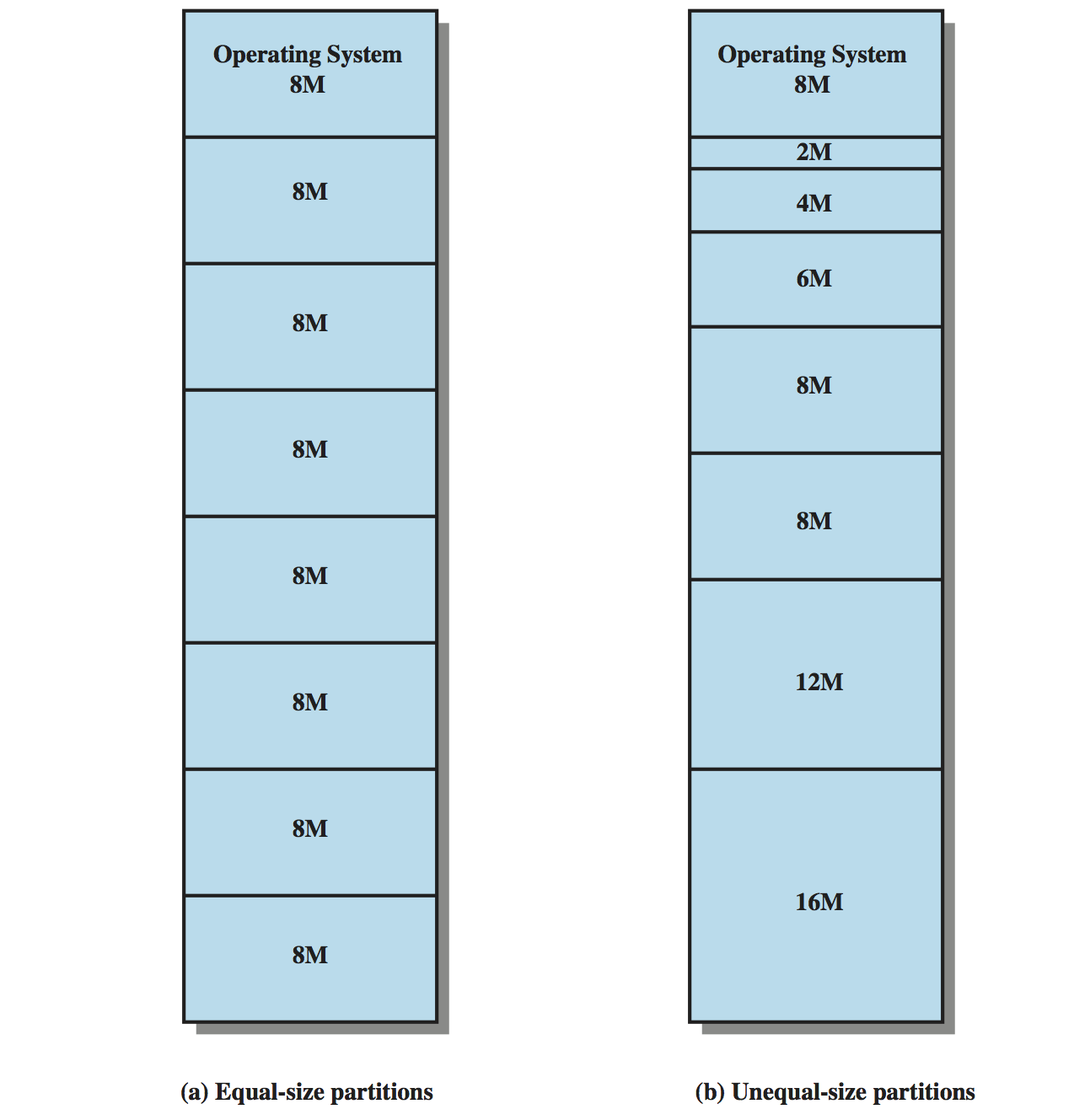
Từ đó ta có thể giảm bớt hiện tượng External Fragmentation bằng cách Compact (cô động) các Internal Fragmentation lại, thay vì chia RAM thành các phân đoạn bằng nhau thì ta có thể chia chúng một cách linh hoạt hơn như hình sau:
Paging
Các OS hiện đại không nhất thiết phải cấp phát vùng nhớ liên tục trên RAM cho các chương trình, các process của một chương trình hoàn toàn có thể nằm rải rác trên RAM thông qua kỹ thuật Paging (Phân trang).
Kỹ thuật này sẽ chia vùng nhớ trên RAM (gắn với Physical Memory) thành các Frame (khung) có kích thước là lũy thừa của 2 (nằm trong hoảng 512 bytes tới 8192 bytes).
Còn bộ nhớ Logic (gắn với địa chỉ Logic) cũng được chia thành các khối (Block) có cùng kích thước với Frame gọi là Page (trang). Điều này tạo nên đặc điểm của Paging là nó sẽ gây ra External Fragmentation.
Khi này hệ điều hành sẽ theo dõi các Frame đang trống (Free Frames) để khi chạy một chương trình có kích thước bằng n trang (pages), hệ điều hành có thể tìm thấy n trang trống tương ứng để ánh xạ và load nó vào RAM thông qua Bảng trang (Page Table)
Bảng trang (Page Table) là một cấu trúc dữ liệu được hệ điều hành tạo ra để ánh xạ từ địa chỉ của các Trang (Logical Address) sang các Khung trang (Physical Address). Nó hoạt động giống hệt một mảng Array với Index là địa chỉ của Trang còn Value là địa chỉ cơ cở (base address) của Frame tương ứng trong bảng.
Các Logical Adress được CPU tạo ra sẽ tuân theo một bộ khung gồm có Page number (p) và Page offset (d). Trong đó p dùng để làm Index đưa vào Page Table => base address. Với base address có được sẽ kết hợp với d để xác định Frame tương ứng với base address đó (có điểm bắt đầu là base address kết thúc là (base address + p)).

Page Table bắt buộc phải được đặt trong RAM để CPU có thể truy xuất trực tiếp đến nó thông qua Page-table base register (PTBR) và Page-table length register (PTLR).
Sau khi truy xuất được địa của Frame trong Page Table thì CPU lại phải tiếp tục truy xuất đến Frame với địa chỉ đã tim được trước đó. Việc này sẽ khiến cho CPU phải truy xuất bộ nhớ 2 lần, làm giảm hiệu quả khi mà RAM có tốc độ rất chậm so với CPU.
Để giải quyét vấn đề này thì người ta sẽ dùng đến kĩ thuật Caching. Máy tính sẽ được cài đặt một bộ nhớ có tốc độ truy xuất nhanh gọi là associative memory hoặc translation look-aside buffers (TLBs).
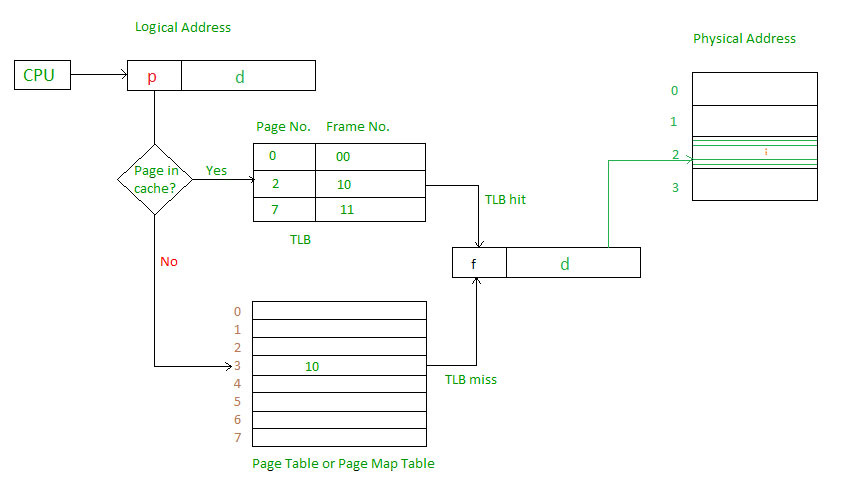
Thì khi truy xuất CPU sẽ ưu tiên tìm trong TLB trước xem có trang cần tìm nằm trong đấy hay không? Nếu có thì lấy luôn đỡ được 1 lần truy xuất RAM. Nếu không thì sẽ truy xuất RAM như bình thường đồng thời sẽ cập nhật lại TLB theo các chính sách cập nhật khác nhau.
Để bảo vệ các Page khỏi việc bị các chương trình khác nhau truy xuất đồng thời thì Page Table cũng thường có các Valid Bit sẽ đánh dấu là v nếu Page đó hợp lệ, i nếu Page đó không hợp lệ.
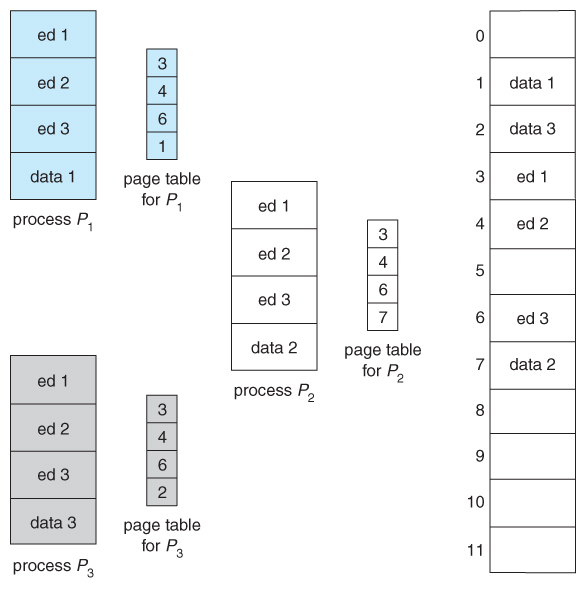
Một vấn đề khác là khi mỗi tiến trình được nạp vào RAM, nó sẽ tạo ra một Page Table riêng cho nó. Nếu 100 tiến trình được nạp vào RAM cùng một lúc sẽ có đến 100 Page Table trong khi mỗi Page Table sẽ có độ dài bằng với số Trang trong RAM. Điều sẽ tiêu tốn một lượng RAM khổng lồ.
Vì thế nên người ta sẽ sử dụng một kỹ thuật gọi là Inverted Page Table:
-
Inverted Page Table: Cả hệ thống chỉ có duy nhất một bảng trang.
- Số lượng mục trong bảng này đúng bằng số lượng khung trang vật lý (physical frames) thực tế trên RAM.
- Mỗi mục sẽ lưu trữ: (Process-ID, Virtual Address). Tức là: "Khung RAM này hiện đang chứa trang ảo nào của tiến trình nào".
Ưu điểm: Tiết kiệm bộ nhớ (RAM):
- Vì số lượng mục chỉ tỉ lệ thuận với dung lượng RAM vật lý (thứ luôn có hạn), chứ không tỉ lệ thuận với không gian địa chỉ ảo (thứ có thể lên tới hàng Petabyte ở hệ 64-bit), nên nó giúp giảm đáng kể lượng bộ nhớ cần thiết để lưu trữ chính cái bảng trang đó.
Nhược điểm: Tốc độ tìm kiếm chậm
- Trong bảng trang thông thường, CPU dùng số trang làm chỉ số (index) nên tìm phát ra ngay ($O(1)$).
- Trong bảng trang nghịch đảo, khi CPU đưa ra một địa chỉ ảo, hệ thống phải lục soát toàn bộ bảng để xem địa chỉ đó đang nằm ở khung vật lý nào. Việc này giống như tìm một người trong danh sách khách sạn nhưng danh sách lại sắp xếp theo số phòng chứ không phải tên người. Nếu tìm thủ công thì sẽ rất lâu ($O(n)$).
Giải pháp tăng tốc: Hash Table (Bảng băm): Để giải quyết nhược điểm "chậm chạp" nêu trên, người ta sử dụng thêm một Hash Table:
- Hệ thống băm (hash) giá trị (PID + Virtual Page Number).
- Kết quả của hàm băm sẽ trỏ thẳng đến một hoặc một vài mục tiềm năng trong Inverted Page Table.
- Thay vì duyệt hàng vạn dòng, CPU giờ chỉ cần kiểm tra 1 hoặc vài mục. Điều này đưa tốc độ tìm kiếm quay về gần mức tức thời ($O(1)$).
Ví dụ so sánh vui:
- Bảng trang thường: Giống như mỗi học sinh có một danh sách tất cả các ngăn tủ trong trường để đánh dấu cái nào mình đang dùng. (Quá tốn giấy!)
- Bảng trang nghịch đảo: Giống như trên mỗi ngăn tủ dán một cái nhãn ghi: "Ngăn này của em Tèo, lớp 10A". Cả trường chỉ có đúng một danh sách các ngăn tủ. (Tiết kiệm giấy, nhưng muốn tìm em Tèo ở đâu thì phải đi xem từng cái nhãn – trừ khi có một sơ đồ băm hỗ trợ).
Shared Pages
Một kỹ thuật khác cũng được dùng trong quản lý bộ nhớ là Shared Pages (Trang dùng chung). Kỹ thuật này giúp hệ thống "ăn gian" dung lượng RAM bằng cách cho phép nhiều tiến trình sử dụng chung một bản sao dữ liệu giống nhau.
Hãy tưởng tượng bạn mở 10 cửa sổ trình duyệt Chrome. Thay vì nạp 10 bản sao bộ mã nguồn của Chrome vào RAM (cực kỳ tốn kém), hệ điều hành chỉ nạp duy nhất một bản sao. Mã này phải là Read-only (chỉ đọc) và Reentrant (mã có thể vào lại). Các mã nguồn này được gọi là Shared codes.
Reentrant nghĩa là mã đó không bao giờ tự thay đổi chính nó trong khi chạy. Nhờ vậy, nhiều tiến trình có thể nhảy vào thực thi cùng một lúc mà không làm hỏng dữ liệu của nhau.
Ví dụ: Các trình soạn thảo văn bản (Word, Notepad), trình biên dịch (Compilers), hoặc hệ thống cửa sổ (Window systems).
Quy tắc nghiêm ngặt: Mã dùng chung phải xuất hiện tại cùng một vị trí trong không gian địa chỉ logic của tất cả các tiến trình. Tại sao? Vì các lệnh nhảy (jump) hoặc gọi hàm bên trong mã đó trỏ đến các địa chỉ cụ thể. Nếu mỗi tiến trình đặt mã này ở một địa chỉ khác nhau, các lệnh nhảy sẽ bị sai lệch hoàn toàn.
Mỗi tiến trình tuy dùng chung mã nguồn nhưng bản chất nó là khác nhau do đó dữ liệu và các đoạn mã nguồn khác phát sinh phải được tách biệt. Mỗi tiến trình giữ một bản sao riêng biệt cho phần mã và dữ liệu không chia sẻ. Ví dụ: Nếu bạn đang gõ văn bản trong Word, thì nội dung bài viết của bạn là Private Data. Dù bạn và người khác cùng dùng chung mã nguồn của chương trình Word, nhưng bài viết của bạn không thể "trộn lẫn" vào bài viết của họ. Vị trí: Các trang dành cho mã và dữ liệu riêng này có thể nằm ở bất cứ đâu trong không gian địa chỉ logic, không cần phải đồng nhất như phần mã dùng chung.
Kỹ thuật này giống như việc cả xóm dùng chung một thư viện (Shared Code) để đọc sách, nhưng mỗi người tự mang theo cuốn sổ tay riêng (Private Data) để ghi chép.
Tiết kiệm RAM: Giảm thiểu việc nạp trùng lặp các thư viện hệ thống khổng lồ (như .dll trên Windows hay .so trên Linux).
Tốc độ: Khởi động ứng dụng nhanh hơn vì mã nguồn có thể đã nằm sẵn trên RAM từ trước do một ứng dụng khác đang dùng.
Segmentation
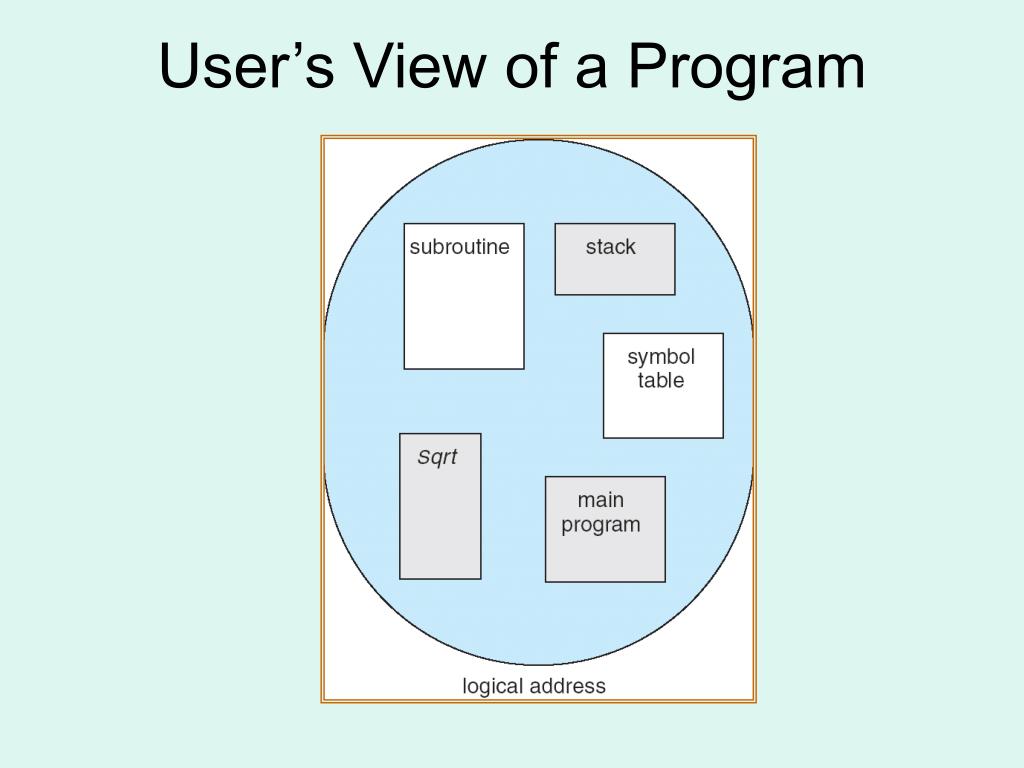
Đây cũng là một kĩ thuật để quản lý bộ nhớ khá tương đồng với Paging nhưng theo góc nhìn của người sử dụng, lập trình viên và chương trình máy tính. Khác với Paging chỉ coi chương trình là một dải địa chỉ tuyến tính, Segmentation coi chương trình là một tập hợp các khối logic (segments).
Mỗi segment có một tên gọi và ý nghĩa riêng: main program, stack, subroutine, symbol table, các mảng dữ liệu, vạch toán Sqrt, v.v.
Các đoạn này không cần phải có kích thước bằng nhau và không cần nằm cạnh nhau trong RAM.
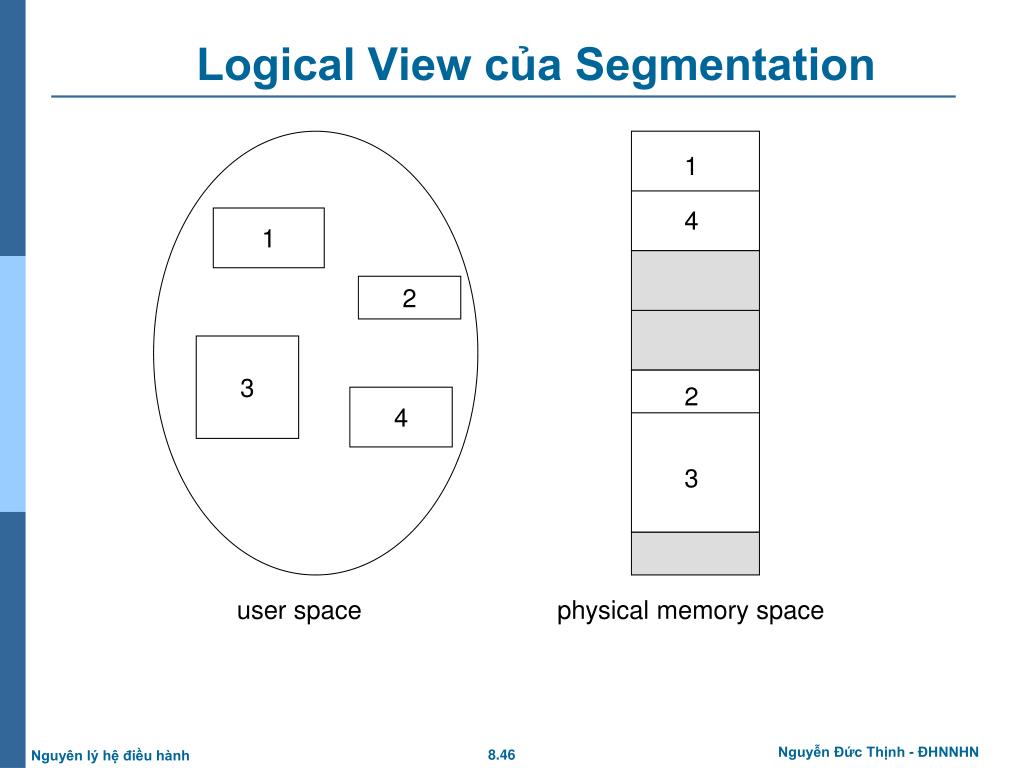
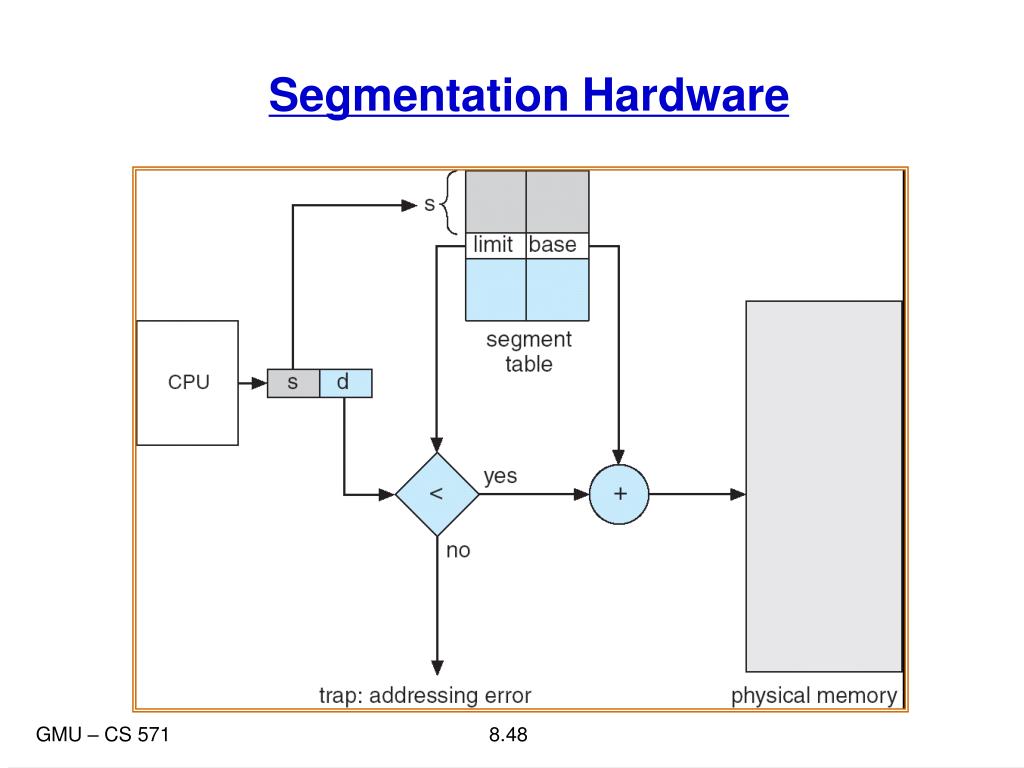
Để máy tính hiểu được "góc nhìn" này, hệ thống sử dụng một cấu trúc địa chỉ 2 thành phần (tuple):
- Bảng phân đoạn (Segment Table): Mỗi dòng trong bảng (entry) chứa:
- Base: Địa chỉ vật lý nơi phân đoạn đó bắt đầu trong RAM.
- Limit: Chiều dài (kích thước) của phân đoạn đó.
- Các thanh ghi hỗ trợ:
- STBR (Segment-table base register): Trỏ đến vị trí của bảng phân đoạn trong RAM.
- STLR (Segment-table length register): Lưu số lượng phân đoạn mà chương trình đang dùng. Một địa chỉ $s$ chỉ hợp lệ nếu $s < STLR$.
Quy trình dịch địa chỉ (Address Translation):
- CPU đưa ra địa chỉ logic $(s, d)$.
- Hệ thống kiểm tra: Nếu $d < limit$ của đoạn $s$ thì mới cho phép đi tiếp. Nếu không, máy sẽ báo lỗi "Addressing error" (Trap).
- Địa chỉ vật lý cuối cùng $= base + d$.
Bảo vệ (Protection): Mỗi dòng trong bảng phân đoạn có các bit đặc quyền: Read/Write/Execute. Ví dụ: Bạn có thể thiết lập để đoạn Code chỉ cho phép "Execute" (chạy) chứ không cho phép "Write" (sửa đổi).
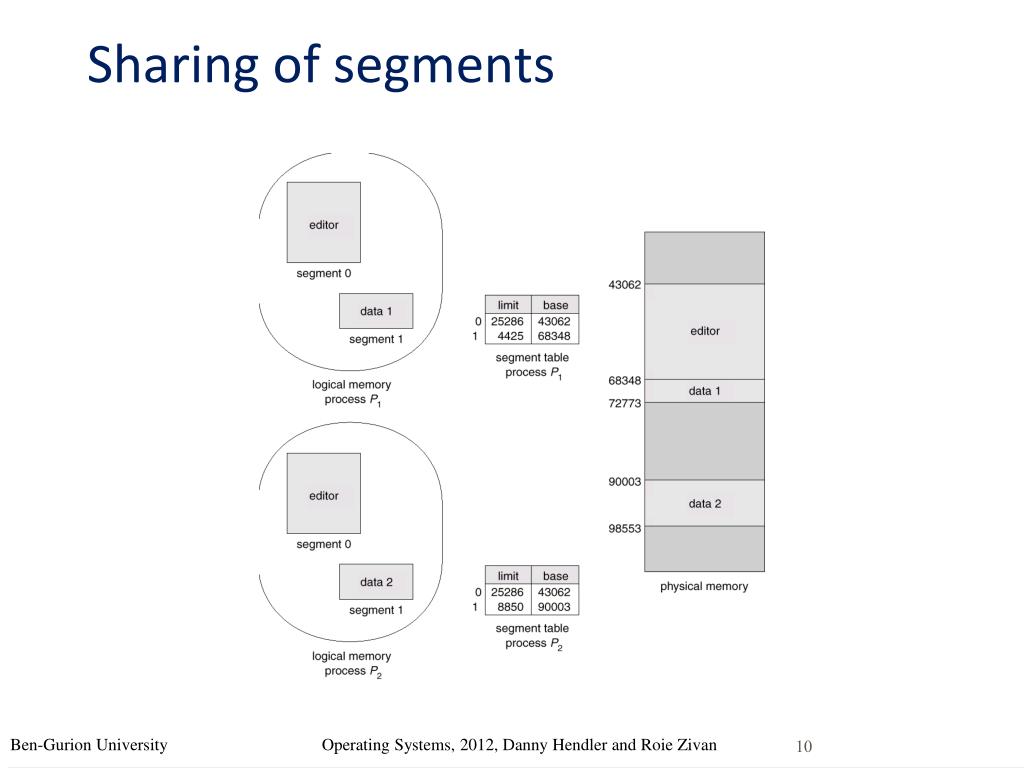
Chia sẻ (Sharing): Hai tiến trình khác nhau có thể dùng chung một phân đoạn (ví dụ: bộ mã nguồn của một trình soạn thảo văn bản - Editor). Trong bảng phân đoạn của cả hai, dòng tương ứng sẽ cùng trỏ về một địa chỉ base vật lý giống nhau.
Cấp phát (Allocation): Vì các đoạn có kích thước khác nhau, việc tìm chỗ trống trong RAM giống như trò chơi xếp hình. Hệ điều hành thường dùng thuật toán First-fit hoặc Best-fit.

Vấn đề: Dễ gây ra Phân mảnh ngoại vi (External fragmentation) — RAM bị chia cắt thành nhiều lỗ hổng nhỏ đến mức không đủ nhét vừa một phân đoạn mới nào.
Giải pháp MULTICS: Phân đoạn kết hợp Phân trang
Hệ thống MULTICS đã giải quyết nhược điểm "phân mảnh" của Segmentation bằng cách kết hợp nó với Paging.
Cơ chế: Thay vì để một phân đoạn nằm liên tục trong RAM, MULTICS chia nhỏ từng phân đoạn đó thành các trang (pages).
Sự thay đổi: Lúc này, mục trong bảng phân đoạn (Segment-table entry) sẽ không chứa địa chỉ cơ sở của phân đoạn nữa. Thay vào đó, nó chứa địa chỉ cơ sở của một Bảng trang (Page Table) dành riêng cho phân đoạn đó.
Lợi ích: Vừa giữ được sự logic của Segmentation, vừa tận dụng được khả năng quản lý RAM linh hoạt của Paging (không lo phân mảnh ngoại vi).
Tóm lại: - Segmentation là quản lý bộ nhớ theo "kiểu con người". - Paging là quản lý bộ nhớ theo "kiểu máy móc". - MULTICS (Hybrid) là sự kết hợp hoàn hảo nhất, được áp dụng trong hầu hết các CPU và Hệ điều hành hiện đại ngày nay.
Tài liệu tham khảo:
- Abraham Silberschartz, Peter Baer Galvin, Greg Gagne, Operating System Concepts, 9th Edition.
- GeeksForGeeks, Logical and Physical Address in Operating System, Có sẵn tại: GeeksforGeeks (Truy cập năm 2025).
← Quay lại trang chủ