Basic Concepts In Artificial Neural Network
Ngày đăng: 2026-03-25
Lời nói đầu
Artificial Neural Network (ANN) là các mô hình máy tính được lấy cảm hứng từ cấu trúc phức tạp và chức năng của mạng lưới tế bào thần kinh sinh học. Bài viết này sẽ tóm gọn các khái niệm, kiến trúc cơ bản và cách một mạng nơ-ron thực sự "học" từ dữ liệu.
Nguyên lý cơ bản của Artificial Neural Network
Cách não bộ sinh học Biology Neural Network hoạt động
Vì ANNs bắt chước cách hoạt động của não người nên ta sẽ bắt đầu từ việc tìm hiểu cách mà não bộ xử lý và lưu trữ thông tin.
Bộ não con người là một hệ thống xử lý thông tin song song, phi tuyến tính và cực kỳ phức tạp, có khả năng học tập, ghi nhớ và khái quát hóa các thông tin. Nó được cấu tạo từ $10^{11}$ tế bào thần kinh (gọi là nơ-ron) liên kết chặt chẽ với nhau tạo thành một mạng lưới.
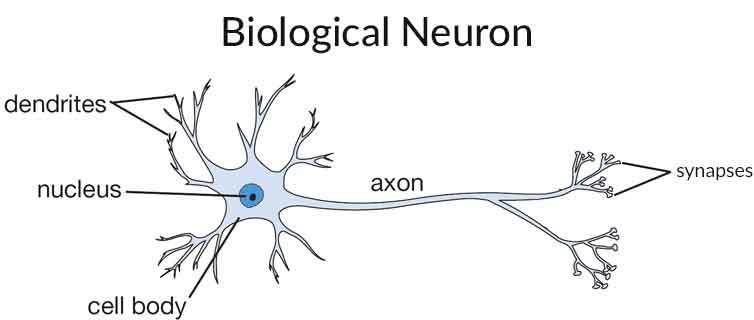
Mỗi nơ-ron sinh học có cấu trúc cơ bản gồm 3 thành phần chính:
- Thân tế bào (Soma/Cell nucleus): Đóng vai trò là trung tâm tổng hợp các tín hiệu.
- Sợi nhánh (Dendrites): Đóng vai trò tiếp nhận các tín hiệu điện (xung thần kinh) từ các nơ-ron lân cận.
- Sợi trục (Axon): Đóng vai trò truyền tín hiệu đi.
Quá trình xử lý: Khi một nơ-ron hoạt động, các sợi nhánh sẽ nhận thông tin. Thân tế bào có chức năng tổng hợp tất cả các tín hiệu đầu vào này. Khi tổng các tín hiệu nhận được vượt qua một ngưỡng giới hạn nhất định, nơ-ron sẽ "phát hỏa" (fire) và truyền tín hiệu đầu ra dọc theo sợi trục để đi đến các nơ-ron khác.
Quá trình học tập: Điểm giao tiếp giữa hai nơ-ron được gọi là khớp thần kinh (synapse). Khi chúng ta học hỏi hoặc phản ứng với các kích thích từ môi trường, độ mạnh yếu của các kết nối khớp thần kinh này sẽ thay đổi (tính dẻo của khớp thần kinh - synaptic plasticity), qua đó giúp não bộ ghi nhớ và thích nghi với các kinh nghiệm.
Cách mà Mạng nơ-ron nhân tạo Artificial Neural Network mô phỏng lại não người
ANN mô phỏng lại cấu trúc tiếp nhận, tính toán tổng hợp, kích hoạt và điều chỉnh kết nối của não bộ con người ở mức độ đơn giản hơn rất nhiều bằng toán học. Trong ANN, các nơ-ron nhân tạo (còn gọi là các nút - nodes) sẽ gồm các thành phần tương ứng trong BNN như sau:
- Sợi nhánh (Dendrites) -> Dữ liệu đầu vào (Inputs): Các biến số đầu vào của mô hình đại diện cho tín hiệu nhận được từ môi trường
- Khớp thần kinh (Synapses) -> Trọng số (Weights): Các liên kết giữa các nơ-ron nhân tạo đi kèm với một giá trị "trọng số". Trọng số này đóng vai trò giống như sức mạnh của khớp thần kinh, quyết định mức độ ảnh hưởng của dữ liệu đầu vào đó.
- Nhân tế bào (Soma) -> Nút tính toán (Nodes): Nơi thực hiện phép tính toán gom thông tin.
- Sợi trục (Axon) -> Đầu ra (Output): Kết quả dự đoán được truyền đi.
Quá trình xử lý thông tin trên ANN: Cũng giống như cách mà não bộ xử lý và tổng hợp tín hiệu điện, các nodes trong ANN thực hiện một hàm tính tổng có trọng số của các đầu vào nhận được:
Sau đó, thay vì một "ngưỡng sinh học", ANN đưa tổng số này qua một Hàm kích hoạt (activation function) để đưa ra kết quả cuối cùng. Hàm kích hoạt này tạo ra tính phi tuyến tính, cho phép mạng học được các mẫu dữ liệu phức tạp.
Quá trình học tập (Training): Trong sinh học, việc học xảy ra nhờ các kích thích bên ngoài; còn trong ANN, "kích thích" chính là tập dữ liệu huấn luyện (training data) chứa các cặp đầu vào - đầu ra thực tế. Khi mạng đưa ra dự đoán sai lệch so với thực tế, sai số đó đóng vai trò như một "phản hồi tiêu cực". Mạng nơ-ron nhân tạo học cách thích nghi bằng cách liên tục điều chỉnh các trọng số (weights) của các kết nối, tương tự như cách não bộ củng cố hoặc làm suy yếu các khớp thần kinh.
Cấu trúc các lớp (Layers) trong Mạng nơ-ron
Một mạng nơ-ron nhân tạo thông thường được tổ chức thành ba loại lớp chính:
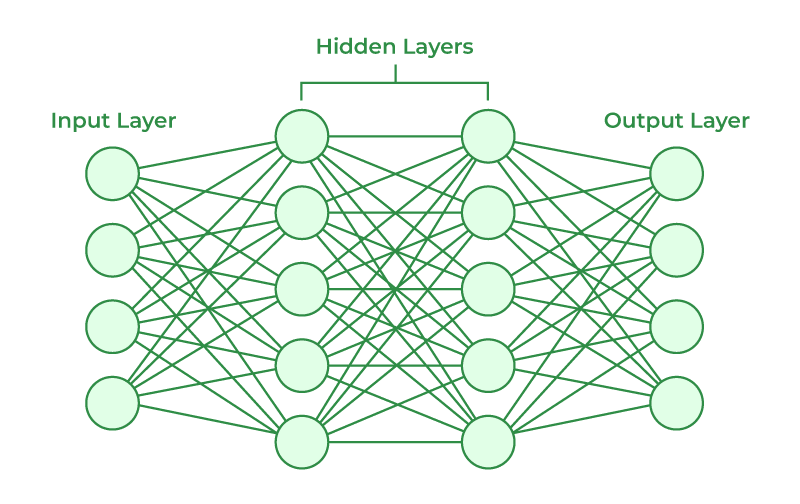
Lớp đầu vào (Input Layer): Đây là nơi trực tiếp tiếp nhận dữ liệu đầu vào đại diện cho các đặc trưng (features) của bài toán. Lớp này không thực hiện bất kỳ phép tính toán nào, mà chỉ đóng vai trò truyền dữ liệu đến lớp tiếp theo.
Lớp ẩn (Hidden Layers): Nằm giữa lớp đầu vào và đầu ra, đây là nơi mạng thực hiện các phép biến đổi toán học nhằm trích xuất đặc trưng và học các quy luật phức tạp. Một mạng có thể có một lớp ẩn (mạng nông) hoặc nhiều lớp ẩn xếp chồng lên nhau (mạng học sâu).
Lớp đầu ra (Output Layer): Là lớp cuối cùng đưa ra dự đoán hoặc kết quả của mô hình. Cấu trúc và hàm kích hoạt của lớp này được lựa chọn dựa trên bài toán cụ thể (ví dụ: hàm linear cho dự đoán giá trị liên tục, hàm sigmoid cho phân loại nhị phân, hoặc hàm softmax cho phân loại nhiều lớp).
Các hàm kích hoạt thông dụng trong ANN:
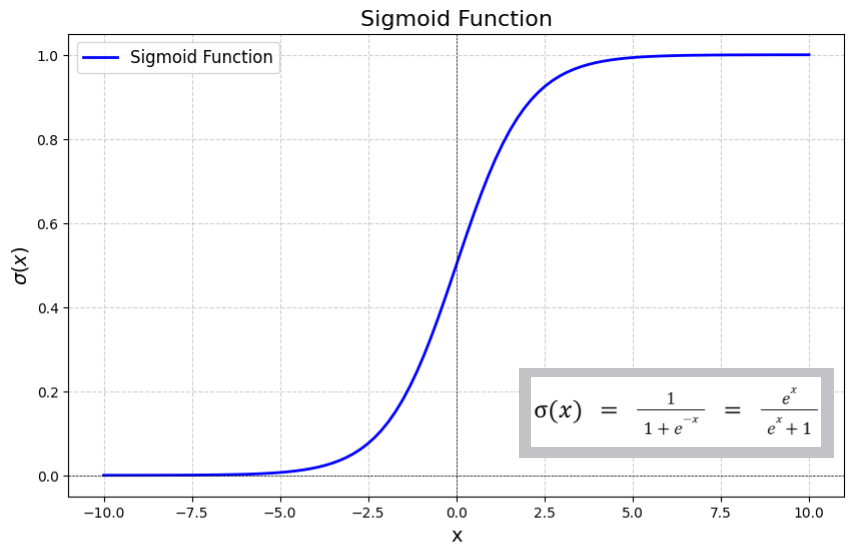
Sigmoid Function: Ánh xạ mọi giá trị đầu vào về khoảng (0,1). Rất hữu ích khi mô hình cần dự đoán xác suất hoặc trong các bài toán phân loại nhị phân.
Công thức: $\sigma = \frac{1}{1+e^{-x}}$
Tanh (Hyperbolic Tangent): Ánh xạ giá trị vào khoảng [−1,1] với tâm đối xứng tại 0. Thường được ưu tiên hơn sigmoid trong các lớp ẩn, đặc biệt là trong mạng nơ-ron hồi tiếp (RNN).
Công thức: $f(x) = tanh(x) = \frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} = \frac{sinh(x)}{cosh(x)}$

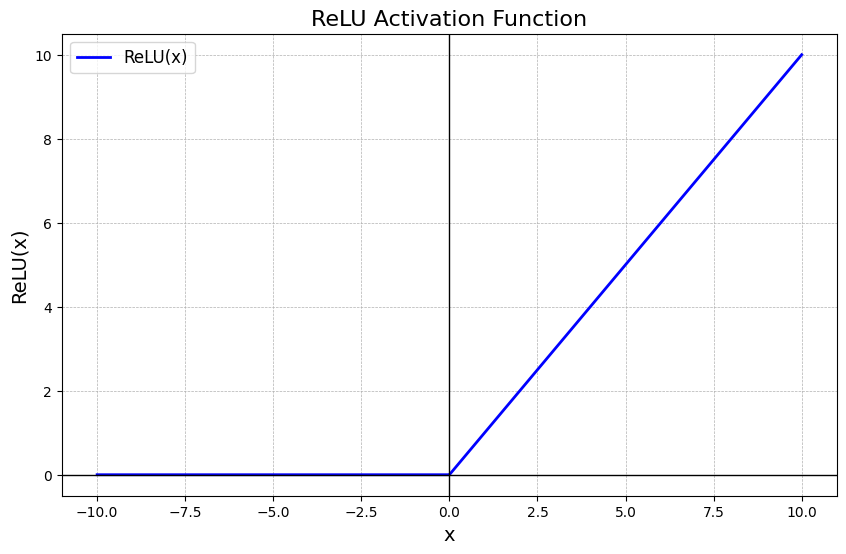
ReLU (Rectified Linear Unit): Đây là hàm kích hoạt được sử dụng rộng rãi nhất hiện nay vì tính toán nhẹ, không bị bão hòa ở miền dương, giúp khắc phục tình trạng triệt tiêu đạo hàm (vanishing gradient) trong các mạng sâu.
Công thức: $f(x) = max(0, x)$
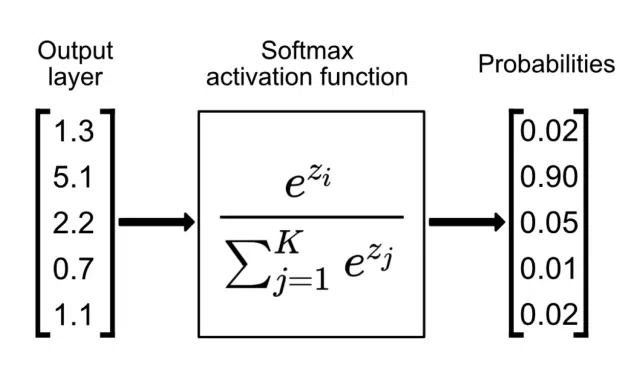
Softmax: Thường được áp dụng ở lớp đầu ra để chuyển đổi kết quả thành một phân phối xác suất mà tổng bằng 1, cực kỳ quan trọng cho bài toán phân loại đa lớp.
Công thức: $\sigma(z_i)=\frac{e^{z_i}}{\sum_{j=1}^{n} e^{z_j}}$
Các loại ANNs thông dụng:
Mạng truyền thẳng (Feedforward Neural Network - FNN):
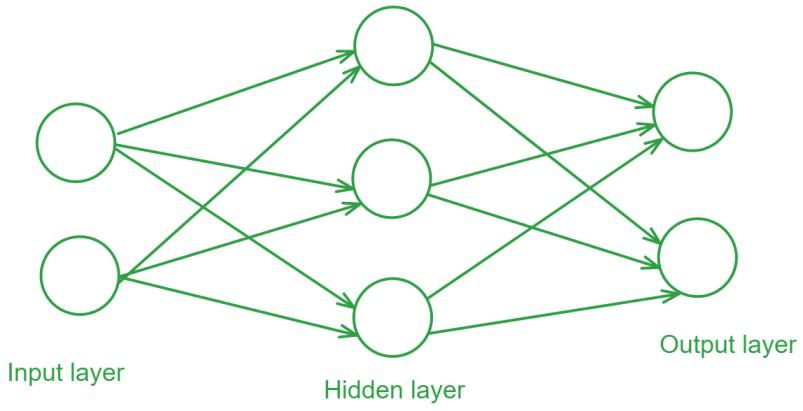
FNN là một trong những kiến trúc ANN cơ bản và đơn giản nhất. Trong mạng này, dòng dữ liệu chỉ di chuyển theo một hướng duy nhất: từ lớp đầu vào (input layer), đi xuyên qua một hoặc nhiều lớp tính toán ẩn (hidden layers) và đi đến thẳng lớp đầu ra (output layer). Đặc điểm nhận dạng cốt lõi của FNN là hoàn toàn không có bất kỳ vòng lặp hay chu trình nào, nghĩa là thông tin không bao giờ được truyền ngược lại các lớp phía trước.
Theo như định nghĩa cơ bản, các mô hình FNN đơn giản nhất (như Perceptron một lớp) không sử dụng thuật toán lan truyền ngược (backpropagation) phức tạp mà chỉ điều chỉnh trọng số thông qua quy tắc cập nhật trực tiếp từ sai số. Tuy nhiên, cần lưu ý thêm rằng ở các biến thể hiện đại hơn với nhiều lớp ẩn (Multi-Layer Perceptron), người ta vẫn ứng dụng backpropagation để huấn luyện. FNN chủ yếu được ứng dụng để giải quyết các bài toán phân loại và hồi quy cơ bản.
Mạng nơ-ron tích chập (Convolutional Neural Network - CNN):

CNN là mô hình được thiết kế đặc thù nhằm xử lý các loại dữ liệu có cấu trúc dạng lưới, tiêu biểu nhất là hình ảnh 2D. Kiến trúc này bao gồm các lớp tích chập (convolutional layers) áp dụng các bộ lọc (filters hay kernels) quét qua dữ liệu để trích xuất các đặc trưng không gian cục bộ.
Hoạt động của CNN được đặc trưng bởi cơ chế chia sẻ tham số (parameter sharing) và kết nối thưa (sparse connections), giúp giảm thiểu đáng kể khối lượng tính toán. Trong quá trình xử lý, các lớp đầu tiên thường nhận diện những đặc trưng cơ bản (như đường viền, góc cạnh), và các lớp sâu hơn sẽ kết hợp chúng lại để nhận diện các cấu trúc phức tạp (như khuôn mặt, đồ vật). Nhờ vậy, CNN mang lại hiệu quả cực kỳ cao trong các tác vụ nhận dạng hình ảnh, nhận dạng giọng nói và phân tích video.
Mạng nơ-ron hồi tiếp (Recurrent Neural Network - RNN):

RNN là mô hình được thiết kế chuyên biệt để xử lý dữ liệu dạng chuỗi tuần tự (sequential data) như chuỗi thời gian, câu chữ văn bản hay tín hiệu âm thanh. Điểm khác biệt lớn nhất của RNN so với các mạng khác là sự xuất hiện của các vòng lặp phản hồi (feedback loops hay self-loops) chính là các mũi tên từ Hidden Layer sau về Hidden Layer trước trong ảnh.
Những vòng lặp này cho phép thông tin từ các bước thời gian trước đó (quá khứ) được truyền lại làm đầu vào cho các tính toán ở bước hiện tại, mang lại cho mạng khả năng "ghi nhớ" (memory) trạng thái của chuỗi. Chức năng này giúp RNN có thể đưa ra dự đoán dựa trên toàn bộ ngữ cảnh dữ liệu từ trước đến nay, biến nó trở thành mô hình lý tưởng để giải quyết các bài toán phức tạp đòi hỏi sự liên kết về mặt thời gian hoặc thứ tự, như nhận dạng giọng nói, dịch máy, mô hình hóa ngôn ngữ và dự báo chuỗi thời gian.
Cách Mạng Nơ-ron "Học" (Learning Algorithms)
Quá trình học của Mạng nơ-ron nhân tạo (ANN) về bản chất là một vòng lặp tối ưu hóa liên tục nhằm tìm ra bộ tham số (trọng số và độ chệch) tốt nhất để mô hình đưa ra dự đoán chính xác. Dưới đây là 4 bước cốt lõi:
1. Lan truyền tiến (Forward Propagation)
Đây là hành trình dữ liệu đi từ lớp đầu vào (input layer), xuyên qua các lớp ẩn (hidden layers) và cuối cùng tới lớp đầu ra (output layer) để tạo ra kết quả dự đoán. Tại mỗi lớp ẩn $l$, mạng nơ-ron thực hiện hai phép toán cơ bản trên mỗi nơ-ron:
- Tính tổng tuyến tính ($z^{(l)} = W^{(l)}a^{(l-1)} + b^{(l)}$): Mạng sẽ lấy vector dữ liệu đầu ra của lớp ngay trước đó ($a^{(l-1)}$) nhân với ma trận trọng số của lớp hiện tại ($W^{(l)}$), sau đó cộng thêm một vector độ chệch ($b^{(l)}$). Phép toán này nhằm tổng hợp thông tin và đánh giá tầm quan trọng của các tín hiệu đầu vào.
- Áp dụng hàm kích hoạt ($a^{(l)} = f(z^{(l)})$): Kết quả tuyến tính $z^{(l)}$ tiếp tục được đưa qua một hàm kích hoạt phi tuyến $f$ (như ReLU, Sigmoid, Tanh) để tạo ra giá trị kích hoạt $a^{(l)}$. Bước này cực kỳ quan trọng vì nó bẻ cong không gian dữ liệu, giúp mạng có khả năng học được các mối quan hệ phức tạp, phi tuyến tính mà các phép toán cộng trừ nhân chia thông thường không làm được. Giá trị $a^{(l)}$ này lại tiếp tục trở thành đầu vào cho lớp tiếp theo, cứ thế cho đến khi ra được dự đoán cuối cùng.
2. Hàm mất mát (Loss Functions)
Sau khi lan truyền tiến đưa ra dự đoán $\hat{y}$, chúng ta cần một thước đo để biết dự đoán này sai lệch bao nhiêu so với nhãn thực tế $y$. Hàm mất mát chính là thước đo đó, đóng vai trò như một "kim chỉ nam" để mạng biết mình đang làm tốt hay tệ.
- Cross-Entropy Loss: Đây là hàm tiêu chuẩn cho các bài toán phân loại (ví dụ: nhận diện ảnh chó/mèo). Nó đo lường sự khác biệt giữa hai phân phối xác suất: phân phối của nhãn thực tế và phân phối xác suất do mô hình dự đoán. Hàm này thường được kết hợp với lớp đầu ra dùng hàm kích hoạt Sigmoid (cho phân loại nhị phân) hoặc Softmax (cho phân loại đa lớp).
- Mean Squared Error (MSE - Sai số bình phương trung bình): Hàm này được dùng chủ yếu cho các bài toán hồi quy (dự đoán các giá trị liên tục như giá nhà, nhiệt độ). MSE tính trung bình cộng của bình phương các hiệu số giữa giá trị dự đoán và giá trị thực tế.
3. Lan truyền ngược (Backpropagation)
Khi đã biết được mức độ sai sót thông qua Hàm mất mát, mạng cần tìm cách sửa sai. Lan truyền ngược là một thuật toán cực kỳ hiệu quả dựa trên quy tắc chuỗi trong vi phân (chain rule of calculus) để giải quyết vấn đề này.
- Quá trình này bắt đầu từ lớp đầu ra và tính toán ngược dần về lớp đầu vào.
- Tại mỗi bước, nó tính toán đạo hàm riêng (gradient) của hàm mất mát đối với từng trọng số và độ chệch. Gradient này cho biết: Nếu ta thay đổi một trọng số cụ thể lên một lượng nhỏ, thì sai số tổng thể sẽ tăng hay giảm bao nhiêu?.
- Nhờ áp dụng quy hoạch động để lưu trữ và tái sử dụng các tính toán trung gian, thuật toán này phân bổ chính xác "trách nhiệm" gây ra sai số cho hàng triệu tham số trong mạng một cách cực kỳ tiết kiệm tài nguyên.
4. Cơ chế cập nhật trọng số (Weight Update Mechanisms)
Khi đã có được bản đồ chỉ hướng (gradient) từ bước lan truyền ngược, các thuật toán tối ưu hóa sẽ ra lệnh điều chỉnh các trọng số để đưa sai số về mức thấp nhất.
- Gradient Descent: Đây là phương pháp cơ bản nhất. Nó cập nhật các tham số bằng cách bước một bước nhỏ theo hướng ngược lại với hướng của gradient (hướng dốc xuống của hàm mất mát). Kích thước của bước đi này được kiểm soát bởi một siêu tham số gọi là tốc độ học ($\eta$).
- Gradient Descent with Momentum: Trong thực tế, bề mặt hàm mất mát thường có nhiều rãnh hẹp khiến Gradient Descent cơ bản bị dao động (zigzag) qua lại rất chậm chạp. Thuật toán Momentum giải quyết việc này bằng cách cộng thêm một phần "đà" (velocity) từ các lần cập nhật trước đó. Nó giúp mạng duy trì quán tính đi thẳng qua các vùng bằng phẳng và giảm thiểu sự dao động thừa thãi, từ đó hội tụ nhanh hơn.
- Adam (Adaptive Moment Estimation): Đây là một trong những thuật toán tiên tiến và phổ biến nhất hiện nay. Adam thông minh ở chỗ nó tự động điều chỉnh tốc độ học riêng biệt cho từng tham số. Nó kết hợp ưu điểm của Momentum (lưu giữ trung bình của các gradient trong quá khứ để lấy đà) và RMSprop (lưu giữ trung bình bình phương của các gradient để chuẩn hóa tốc độ học). Đồng thời, Adam có thêm cơ chế hiệu chỉnh sai lệch (bias correction) ở những bước lặp đầu tiên, giúp mô hình cực kỳ ổn định và hội tụ với tốc độ rất nhanh.
Bốn bước này được lặp đi lặp lại hàng ngàn, hàng triệu lần qua các lô dữ liệu huấn luyện (mini-batches) cho đến khi mô hình đạt được độ chính xác mong muốn.
Cơ sở toán học trong ANNs
Như đã trình bày ở phía trên thì các ANNs mô phỏng lại hoạt động của não bộ con người ở mức đơn giản nhất thông qua toán học, chủ yếu là phép toán ma trận. Thông qua ma trận thì ta có thể dễ dàng biểu diễn các kết nối nơ-ron trong một ANN.
Giả sử chúng ta có một mạng nơ-ron dùng cho bài toán phân loại nhị phân với kiến trúc như sau:
- Lớp đầu vào: 2 nơ-ron, tương ứng với 2 đặc trưng đầu vào $x_1, x_2$.
- Lớp ẩn: 3 nơ-ron, sử dụng hàm kích hoạt ReLU.
- Lớp đầu ra: 1 nơ-ron, sử dụng hàm kích hoạt Sigmoid để đưa ra xác suất dự đoán.
Thay vì tính toán lẻ tẻ cho từng nơ-ron, toán học cho phép ta gom toàn bộ trọng số (weights) và độ lệch (biases) thành các ma trận và vector. Các tham số được khởi tạo như sau:
-
Vector đầu vào:
-
Ma trận trọng số và độ lệch lớp ẩn:
-
Ma trận trọng số và độ lệch lớp đầu ra:
Quá trình xử lý qua các phép toán ma trận diễn ra như sau:
Bước 1: Tính đầu vào lớp ẩn (Nhân ma trận và cộng vector) Hệ thống sẽ thực hiện phép nhân ma trận $W^{(1)}$ với vector $x$, sau đó cộng vector bias $b^{(1)}$:
Bước 2: Áp dụng hàm kích hoạt lớp ẩn (Phép toán phi tuyến) Hàm ReLU $\max(0, z)$ được áp dụng lên từng phần tử của vector $z^{(1)}$:
Bước 3: Tính đầu vào lớp đầu ra Tiếp tục nhân ma trận giữa $W^{(2)}$ và vector kích hoạt $a^{(1)}$, cộng với $b^{(2)}$:
Bước 4: Áp dụng hàm kích hoạt lớp đầu ra Áp dụng hàm Sigmoid để thu được xác suất cuối cùng:
$\hat{y} = \sigma(z^{(2)}) = \frac{1}{1 + e^{-0.23}} \approx 0.557$ Kết quả $0.557$ là xác suất mà mạng dự đoán đầu vào thuộc về phân lớp 1.
Qua ví dụ trên, có thể thấy toàn bộ mạng nơ-ron thực chất là một hàm toán học khổng lồ. Sự kết hợp của toán học, đặc biệt là Đại số tuyến tính và Giải tích, mang lại những giá trị cốt lõi không thể thay thế:
- Biểu diễn vô cùng nhỏ gọn (Compact Representation): Nếu không dùng ma trận, bạn sẽ phải viết hàng ngàn phương trình cộng dồn đại số độc lập cho từng nơ-ron. Đại số tuyến tính cho phép tổ chức tất cả các kết nối từ một lớp sang lớp tiếp theo vào một biểu thức cực kỳ ngắn gọn: $z = Wx + b$.
- Tối ưu hóa sức mạnh tính toán (Computational Efficiency): Các ngôn ngữ lập trình, thư viện (như TensorFlow, PyTorch) và phần cứng máy tính (đặc biệt là GPU) được thiết kế để tối ưu hóa triệt để các phép nhân ma trận. Nhờ biểu diễn bằng toán học ma trận, máy tính có thể xử lý hàng triệu phép tính song song cùng lúc, giúp quá trình huấn luyện và dự đoán diễn ra nhanh hơn gấp nhiều lần.
- Nền tảng cho quá trình "Học" (Backpropagation): Khả năng học hỏi của ANN phụ thuộc hoàn toàn vào Giải tích (Calculus), đặc biệt là quy tắc chuỗi đa biến (multivariable chain rule). Thuật toán Lan truyền ngược (Backpropagation) sử dụng các phép tính đạo hàm, ma trận Jacobian và ma trận chuyển vị để tính toán gradient của hàm mất mát, từ đó phân bổ chính xác "lỗi" về cho hàng triệu trọng số trong mạng.
- Phân tích và cải tiến (Optimization): Các phương pháp toán học cấp cao (như phân tích ma trận Hessian, tính định thức, đạo hàm bậc hai) giúp các kỹ sư hiểu rõ không gian hàm mục tiêu, giải quyết các rắc rối như "triệt tiêu đạo hàm" (vanishing gradient), cực tiểu cục bộ, hay sử dụng các thuật toán tối ưu hóa như Adam, Momentum để mạng hội tụ hiệu quả.
Nói cách khác, Toán học chính là ngôn ngữ thực sự của Trí tuệ nhân tạo; nó giúp mô hình hóa bộ não sinh học phức tạp thành các phương trình có thể tính toán, lập trình và mở rộng trên hệ thống máy tính.
Tài liệu tham khảo
- Aggarwal, C. C. (2018). Neural Networks and Deep Learning: A Textbook. Springer.
- GeekforGeeks. Artificial Neural Networks and its Applications. [Trực tuyến]. Có sẵn tại: GeeksforGeeks (Truy cập năm 2025).
- Viettel IDC. Artificial Neural Network là gì? Cấu trúc, cách hoạt động và ứng dụng của mô hình này. [Trực tuyến]. Có sẵn tại: Viettel IDC.(Truy cập năm 2025).
- Huy, T. M., & Khang, V. H. N. (2024) Essential Concepts in Artificial Neural Networks.
← Quay lại trang chủ