Hành trình tự build Blog cá nhân bằng Python từ con số 0
Ngày đăng: 2026-03-10
Lời nói đầu
Trang web bạn đang đọc không sử dụng WordPress, không dùng React, và thậm chí không dùng cả các Static Site Generator (SSG) có sẵn như Hugo hay Astro. Nó được build hoàn toàn từ một tệp script Python chưa tới 100 dòng code.
Mục tiêu của tôi khi tạo ra blog này là sự tối giản tuyệt đối (phong cách Web 1.0): không JavaScript thừa thãi, không hiệu ứng màu mè, tốc độ tải trang tính bằng mili-giây, và quan trọng nhất là phải hỗ trợ tốt các định dạng tài liệu của một Kỹ sư Dữ liệu (Data/AI Engineer).
Ý tưởng cốt lõi
Đầu tiên ta sẽ tìm hiểu về quy trình tối ưu để một các bài viết cá nhân được xây dựng.
Các bài viết được đăng lên Server và để có định dạng đẹp, dễ đọc thì các bài viết ấy thường sẽ được viết dưới dạng Markdown, Jupyter Notebook hay thậm chí là một file HTML thuần.
Các bài viết được viết dưới dạng file nội dung thô thì Server phải có một cơ chế render nội dung ấy ra màn hình theo thời gian thực hoặc là sẽ chuyển file đó sang dạng html để trình duyệt hiển thị trên màn hình.
Sau đó thì các bài viết sẽ phải được thêm vào trang chủ bằng một cách nào đó, thông thường nhất thì trang chủ ta sẽ tạo một siêu liên kết từ trang chủ đến các bài viết đó.
Ở dự án này mình sẽ viết nội dung dưới dạng file Markdown hoặc Jupyter Notebook, đồng thời mình sẽ biên dịch nó ra thành các file HTML thay vì tích hợp một dạng realtime render hay các api để nhận file dữ liệu thô và trả về file HTML.
Đây là lựa chọn tối ưu nhất với sự đơn giản, tốc độ load nhanh do không cần đợi render hay convert khi truy cập.
Tất cả có thể được xem như là một quy trình ETL cơ bản:
- Extract (Trích xuất): Đọc các file nội dung thô (
.mdhoặc.ipynb) từ ổ cứng. - Transform (Biến đổi): Biên dịch các file nội dung thô thành các file HTML để trình duyệt render.
- Load (Tải lên): Gắn các nội dung HTML đã dịch đó vào một khung trang web và tạo siêu liên kết từ trang chủ đến nó.
Các ý tưởng trên sẽ là nền tảng để xây dựng nên dự án này.
Lựa chọn Tech Stack:
Ngôn ngữ: Python 3 được chọn vì tính đơn giản, dễ đọc và có nhiều thư viện hỗ trợ cho việc xử lý dữ liệu thô (các file nội dung thô) và chuyển đổi sang html.
Parsing: sử dụng thư viện Markdown (xử lý .md), nbconvert (xử lý .ipynb), python-frontmatter (để đọc tiêu đề file).
Templating: thư viện Jinja2 được dùng để đọc các mẫu do mình thiết kế sẵn và đưa các nội dung html đã được xử lý vào các mẫu sẵn có đó.
Toán học: KaTeX (Render client-side) tích hợp vào các đoạn Script của JavaScript và thực thi trên trình duyệt người dùng để render các công thức, phương trình toán học.
Hosting: Vercel được chọn vì sự đơn giản, đã được liên kết với Github và miễn phí :v
Quá trình xây dựng (continue):
Cấu trúc dự án:
Để bắt đầu ta sẽ cần tạo một cấu trúc dự án như ảnh sau:
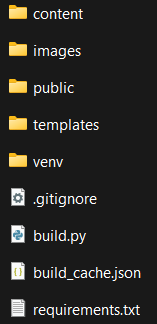
Trong đó thì:
content sẽ là nơi chứa các file .md và .ipynb.
images là nơi chứa các ảnh.
public sẽ chứa các file .html được biên dịch từ các nội dung trong thư mục content. Các file này sẽ được đưa vào trang chủ dưới dạng Hyperlink để người dùng click vào và chuyển hướng đến nó.
templates sẽ chứa các khung để chứa nội dung được biên dịch từ content. Các file .html trong public là thành quả từ các nội dung được biên dịch trong content gắn vào các khung của templates.
venv là thư viện ảo dùng để tải các thư viện mà không làm ảnh hưởng đến hệ thống.
.gitignore dùng để chứa tên các file mà không thêm vào git. Gồm các file và folder như: venv, public (không cần vì khi ta up source lên máy chủ host thì ta sẽ chạy và build lại các file trong content và lưu vào thư mục public trên đó) và pycache (chứa các file object tạm thời khi biên dịch các thư viện, không cần thiết phải up lên host vì source được up lên đấy sẽ được build lại hết).
build_cache.json là một file đặc biệt đóng vai trò như là một bộ đệm (cache). Khi file build.py build các file trong content thì nó sẽ kiểm tra file build_cache.json trước để xem các file sắp build có nội dung nằm trong hoặc thay đổi gì so với build_cache.json hay không? Nếu có thì sẽ build lại và lưu trạng thái mới vào file đệm đó. Còn không thì sẽ lấy luôn nội dung trong file đó và giải mã ra file .html.
requirements.txt: chứa tên các thư viện cần thiết, ta sẽ chạy lệnh sau trong môi trường ảo venv để tải chúng:
sudo pip install -r requirements.txt
Xây dựng chương trình chính
Tiếp theo ta sẽ đi sâu vào file build.py vì đây là thành phần quan trọng nhất trong dự án này:
Khởi tạo thư viện:
import os; from pathlib import Path #dùng để thực hiện các thao tác với file và thư mục trên máy tính
import json #dùng để serialize và deserialize file build_cache.json
import hashlib #tạo hàm bâm MD5 cho các file nội dung và lưu vào build_cache.json cho tiết kiệm
import markdown, frontmatter #dùng để đọc và dịch các file .md
import nbformat; from nbconvert import HTMLExporter #dùng để đọc và dịch file .ipynb
import re #dùng Regular Expression (Regex) để cắt chữ
from jinja2 import Environment, FileSystemLoader #dùng để đọc các khung trong thư mục templates, kết hợp chúng với nội dung để tạo ra các trang html
from datetime import datetime #kiểu dữ liệu ngày giờ
Khởi tạo các hằng số:
# Cấu hình đường dẫn
CONTENT_DIR = "content"
TEMPLATE_DIR = "templates"
PUBLIC_DIR = "public"
CACHE_FILE = "build_cache.json"
BASE_URL = "https://....."
Bắt đầu vào đoạn code chính. Ta sẽ khởi tạo hàm get_file_hash() để hash file nội dung và lưu vào bộ đêm build_cache.json.
def get_file_hash(filepath):
"""Hàm băm MD5 nội dung file. Bất kỳ thay đổi 1 ký tự nào cũng làm đổi mã này."""
with open(filepath, "rb") as f:
return hashlib.md5(f.read()).hexdigest()
Giải thích: Hàm này mở file lên ở chế độ đọc nhị phân ("rb"). Nó dùng thuật toán MD5 băm toàn bộ nội dung thành một chuỗi mã duy nhất (ví dụ: 8a2b...). Chỉ cần bạn thêm 1 dấu phẩy vào file bài viết, mã này sẽ thay đổi hoàn toàn.
Hàm chính dùng cho việc xây dựng các trang nội dung và lưu vào public:
def build_site():
Path(PUBLIC_DIR).mkdir(parents=True, exist_ok=True) # Tạo thư mục public nếu chưa có
# Nạp các khung (template) HTML vào bộ nhớ
env = Environment(loader=FileSystemLoader(TEMPLATE_DIR))
post_template = env.get_template("post.html")
index_template = env.get_template("index.html")
# 1. TẢI BỘ NHỚ ĐỆM (CACHE)
if os.path.exists(CACHE_FILE):
with open(CACHE_FILE, "r", encoding="utf-8") as f:
cache = json.load(f)
else:
cache = {}
new_cache = {} # Biến chứa bộ nhớ đệm cho lần chạy CẬP NHẬT này
posts_data = [] # Danh sách lưu thông tin các bài viết để đẩy ra trang chủ
# Chuẩn bị đối tượng để dịch file Jupyter sang HTML
html_exporter = HTMLExporter()
html_exporter.template_name = 'basic'
# 2. QUÉT VÀ PHÂN LOẠI FILE
for filename in os.listdir(CONTENT_DIR):
filepath = os.path.join(CONTENT_DIR, filename)
# Bỏ qua các file rác (như .DS_Store trên Mac), chỉ quan tâm .md và .ipynb
if not (filename.endswith(".md") or filename.endswith(".ipynb")):
continue
slug = filename.rsplit('.', 1)[0] # Cắt bỏ phần đuôi file (VD: bai-1.md -> bai-1)
current_hash = get_file_hash(filepath) # Tạo mã hash cho file hiện tại
output_path = os.path.join(PUBLIC_DIR, f"{slug}.html") # Đường dẫn file HTML sẽ sinh ra
# 3. CHỐT CHẶN CACHE
if filename in cache and cache[filename]["hash"] == current_hash and os.path.exists(output_path):
print(f"[~] Bỏ qua (Đã cache): {filename}")
# Bơm thẳng dữ liệu từ cache vào danh sách bài viết mà không cần dịch lại
posts_data.append(cache[filename]["meta"])
new_cache[filename] = cache[filename] # Giữ lại thông tin này cho bộ nhớ mới
continue # Lập tức nhảy sang file tiếp theo, bỏ qua toàn bộ code bên dưới
print(f"[*] Đang biên dịch bài mới/đã sửa: {filename}")
post_info = {}
html_content = ""
# XỬ LÝ ĐỊNH DẠNG .MD
if filename.endswith(".md"):
with open(filepath, "r", encoding="utf-8") as f:
post = frontmatter.load(f) # Tách phần --- ở đầu file ra
# Dịch Markdown sang HTML, bật các plugin hỗ trợ Code, Bảng biểu và Toán học
html_content = markdown.markdown(
post.content,
extensions=['fenced_code', 'tables', 'mdx_math']
)
# Lấy tiêu đề và ngày tháng từ Frontmatter
post_info = {
"title": post.metadata.get("title", slug.replace("-", " ").title()),
"date": post.metadata.get("pubDate", datetime.today().strftime('%Y-%m-%d')),
"slug": slug
}
# XỬ LÝ ĐỊNH DẠNG .IPYNB
elif filename.endswith(".ipynb"):
with open(filepath, "r", encoding="utf-8") as f:
notebook_node = nbformat.read(f, as_version=4)
(body, resources) = html_exporter.from_notebook_node(notebook_node)
html_content = body
# Dùng Regex tìm ngày tháng nằm ở đầu tên file (VD: 2026-03-21-bai-1.ipynb)
match = re.match(r'^(\d{4}-\d{2}-\d{2})-(.+)$', slug)
if match:
post_info = {
"title": match.group(2).replace("-", " ").title() + " (Notebook)",
"date": match.group(1),
"slug": slug
}
else:
post_info = {
"title": slug.replace("-", " ").title() + " (Notebook)",
"date": datetime.today().strftime('%Y-%m-%d'),
"slug": slug
}
# BƠM VÀO TEMPLATE VÀ LƯU HTML
post_render_data = post_info.copy()
post_render_data["content"] = html_content
final_html = post_template.render(post=post_render_data) # Bơm HTML vào khung giao diện post.html
with open(output_path, "w", encoding="utf-8") as f:
f.write(final_html) # Lưu thành file .html vào thư mục public
# Ghi nhớ lại file này vừa làm xong, lưu mã Hash và Meta để lần sau không làm lại nữa
new_cache[filename] = {
"hash": current_hash,
"meta": post_info
}
posts_data.append(post_info)
print(f"[+] Hoàn tất dịch: {slug}.html")
# Kết thúc vòng lặp For: Lưu toàn bộ trí nhớ mới đè lên file json cũ
with open(CACHE_FILE, "w", encoding="utf-8") as f:
json.dump(new_cache, f, ensure_ascii=False, indent=4)
# LÀM MỚI TRANG CHỦ
posts_data.sort(key=lambda x: x["date"], reverse=True) # Sắp xếp bài mới nhất lên đầu
index_html = index_template.render(posts=posts_data) # Bơm danh sách vào index.html
with open(os.path.join(PUBLIC_DIR, "index.html"), "w", encoding="utf-8") as f:
f.write(index_html)
print("Hoàn tất! Hệ thống đã sẵn sàng.")
if __name__ == "__main__":
build_site()
Đưa source lên Host:
Để cho đơn giản thì mình sẽ dùng Github để lưu trữ code và Vercel để deploy. Quá trình này cực kì đơn giản vì Github và Vercel có liên kết với nhau rất chặt chẽ. Phần khó nằm ở việc Vercel chỉ hỗ trợ native với các công nghệ của JavaScript nhưng dự án của chúng ta được xây dựng trên nền Python. Vì thế nên ta sẽ cần phải thiết lập một vài thứ để Vercel có thể chạy và build các dự án Python của chúng ta.
Demo
Vì hệ thống được thiết kế linh hoạt, mình có thể kết hợp nhiều cú pháp trong cùng một bài viết.
1. Hiển thị Code block (Markdown chuẩn):
def say_hello():
print("Hello, World! Welcome to my minimal blog.")
2. Hiển thị HTML nhúng (Custom UI):
3. Hiển thị Công thức Toán học (LaTeX): Được hỗ trợ bởi thư viện KaTeX, hệ thống có thể render các công thức phức tạp cực kỳ sắc nét. Ví dụ, công thức hàm sigmoid thường dùng trong Machine Learning:
Tài liệu tham khảo
Trong quá trình xây dựng, tôi đã sử dụng các tài liệu sau:
← Quay lại trang chủ